💡 This post is based on the latest CM MES version **v11.1**, although the discussed concepts should also be valid for previous versions.
In today’s dynamic technological landscape, the need to integrate diverse software systems using appropriate communication protocols is increasingly common for delivering comprehensive solutions to complex requirements. While traditional client-server integration has largely relied on the synchronous Request-Response architecture (Synchronous APIs), non-blocking, fire and forget Asynchronous APIs have gained significant traction in recent years, driven by the growing adoption of microservices architecture and its associated server-to-server communication demands.
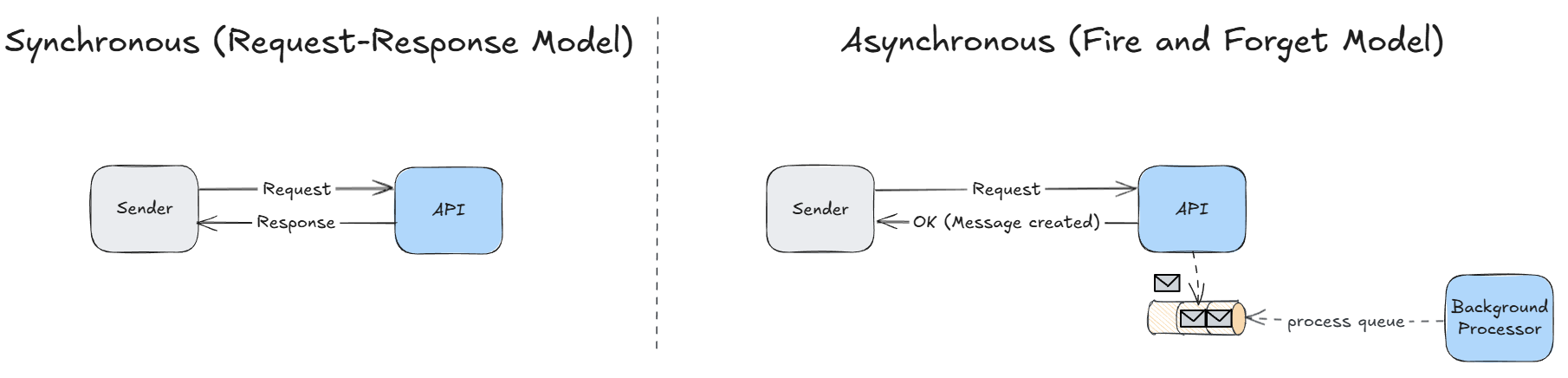
In essence, a Synchronous model requires the caller to wait for the request to be fully processed before receiving a response. Conversely, in an Asynchronous model, the request is stored externally (e.g., database, message queue) for background processing, and the API immediately acknowledges receipt to the caller. In scenarios where immediate process results are not critical, this API architecture offers several key advantages:
➡️ Long-running tasks: For operations expected to take more than a few seconds (e.g., image/video processing), it’s a best practice to provide immediate feedback to the caller while processing the request in the background.
➡️ Scalability: By offloading processing to background workers, the API can handle a higher volume of incoming requests without being blocked by the processing time of each operation.
➡️ Service decoupling: Request-response models can create tighter dependencies between services. Asynchronous models reduce this coupling by allowing services to communicate indirectly. For instance, Service A can send a message to a storage mechanism, and a background worker can then relay this message to Service B. If Service B is temporarily unavailable, Service A’s functionality remains unaffected.
A frequent requirement in Critical Manufacturing MES project deployments is the ability to integrate with external 3rd party systems such as ERP, PLM, or Asset Management applications. To address this, CM MES provides an internal framework and integration engine designed to handle scenarios where asynchronous communication is required or architecturally preferred. The entire process of message storage and processing is managed within the CM MES ecosystem.
At the core of this mechanism lies the concept of an Integration Entry. An Integration Entry can be conceptually compared to a message in an external message queue system like RabbitMQ. It comprises a set of metadata properties and a body containing the message payload, which can be in virtually any format (e.g., JSON, XML, etc.).
In the next sections, we will take a closer look on how this mechanism works, focusing on three key aspects:
- The setup of the process pipeline, from the initial Host execution to the processing of a message.
- The process by which integration entries are retrieved from the database for processing (pulling).
- Important configurations that can be applied to the integration engine or the Integration Entry itself.
But first, let’s have a quick recap of the basic functionality and configuration of the Integration Engine.
Integration Engine Recap
To aid our understanding, let’s refer to the following diagram from the Documentation Portal:
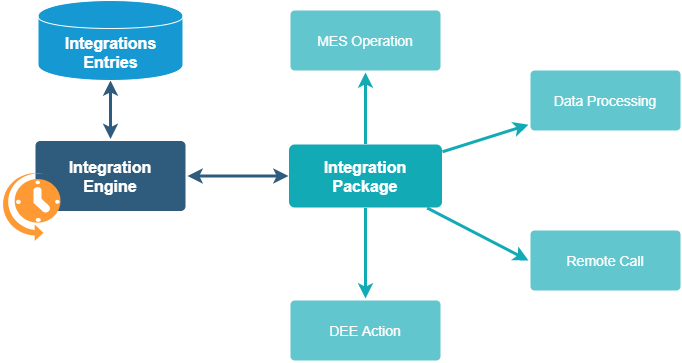
Integration Entries are stored directly within the CM MES database, eliminating the need for external message queues or databases for this mechanism. An IntegrationEntry is an entity type that includes several properties, notably:
- Name: A unique identifier for the integration entry - can virtually be anything, such as a GUID or a consistent naming convention for easy tracking.
- MessageType: Identifies the type of message and is typically used to determine how the integration entry will be processed.
- SourceSystem and TargetSystem: Indicate the originating and destination systems of the message, referencing the
IntegrationSystemlookup table. These can also influence the processing logic. - SystemState: Reflects the current processing status of the Integration Entry (more details below).
- IsRetriable: A flag indicating whether the message should be automatically retried in case of an error.
The actual message payload is stored in a separate but tightly linked entity type, IntegrationMessage, which contains a reference to its corresponding IntegrationEntry.
Integration entries can be created through various means, depending on whether the message is intended for processing by CM MES (Inbound) or for sending from CM MES (Outbound):
- 📨 Inbound: These messages are usually created using the standard
CreateObjectAPI or custom APIs that perform initial processing before creating the integration entry. - Outbound 📨: These messages are created and stored following specific operations within CM MES, typically via DEE Actions or custom services.
The Integration Engine is a background worker framework responsible for processing these entries. We will explore its key components later, but for now, it’s crucial to understand that the engine processes entries based on their SystemState. The following table outlines the main system states of an Integration Entry:
| State | Description |
|---|---|
| Received | The initial state upon creation of the Integration Entry, indicating it’s ready for processing by the engine. |
| Processed | Set after the entry has been successfully processed by the integration logic. |
| Failed | Indicates that an error occurred during the processing of the entry. |
ℹ️ Reprocess Integration Entries
Failed entries can be reprocessed either manually via the System Integration UI Page or automatically using an error handling DEE Action. However, these actions only sets the entry’s IsRetriable flag to True and does not revert the entry’s state to Received. A CmfTimer named RetryIntegrationEntry, running frequently (default every 5 minutes), checks for entries with the IsRetriable flag set. If the maximum retry limit hasn’t been reached, it changes the state back to Received.
Once the integration engine retrieves the next integration entry (or a batch of entries) for processing, it determines the appropriate Integration Package responsible for handling it. An Integration Package is a software library containing an integration handler as its entry point. These packages and handlers are configured in the generic table IntegrationHandler. By default, two integration packages/handlers are registered upon CM MES environment installation:
- SapIntegrationHandler: For direct connection and integration with an SAP instance.
- GenericIntegrationHandler: A versatile handler suitable for simpler integration scenarios.
The mapping between Integration Entries and their corresponding handlers is defined in the smart table IntegrationHandlerResolution. This table allows you to specify which integration package handler will process an entry based on its key properties (SourceSystem, TargetSystem, MessageType).
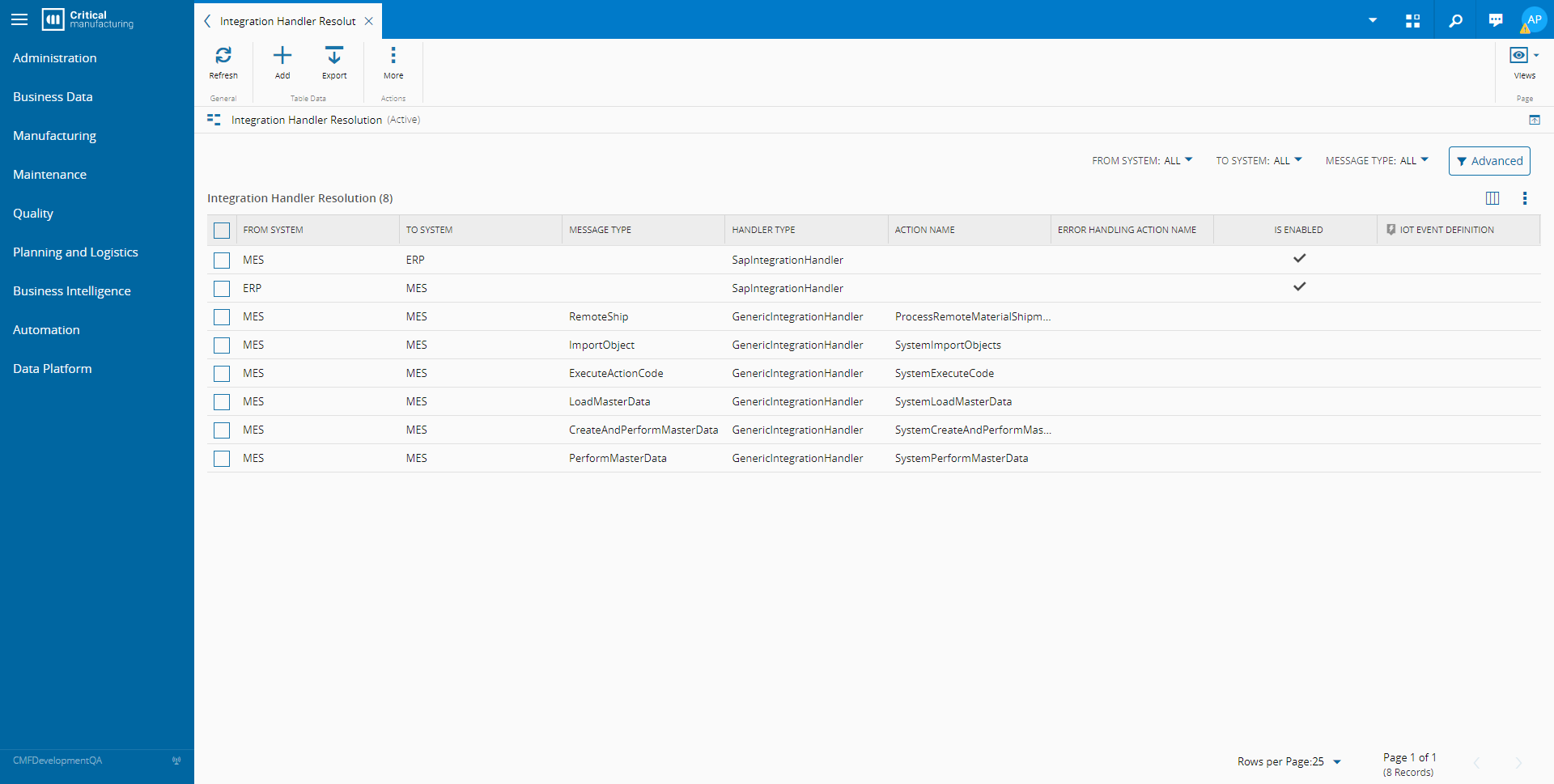
ℹ️ Integration Packages
In most situations, the GenericIntegrationHandler proves sufficient. This package requires you to specify a DEE Action in the ActionName column, which will be executed to process the entry. You can also specify an IotEventDefinition, although low-code logic falls outside the scope of this post.
Custom integration packages can be beneficial when you need to listen for new messages from external systems like message queues and automatically create the corresponding Integration Entries. This advanced topic is also beyond the scope of this discussion.
Let’s now delve into the Integration Engine in more detail. How does this background worker process initiate? What are its constituent components, and how does information flow within it?
The Integration Engine Pipeline Explained
The Integration Engine pipeline is an integral part of the CM MES Host component. Upon Host startup, the StartIntegrationHandler triggers the background creation of this pipeline. You can verify this process by observing the Starting Integration Manager... entry in the host’s logs during startup.
To better visualize the pipeline’s structure and information flow between internal components, the following sequence diagram provides a high-level overview:
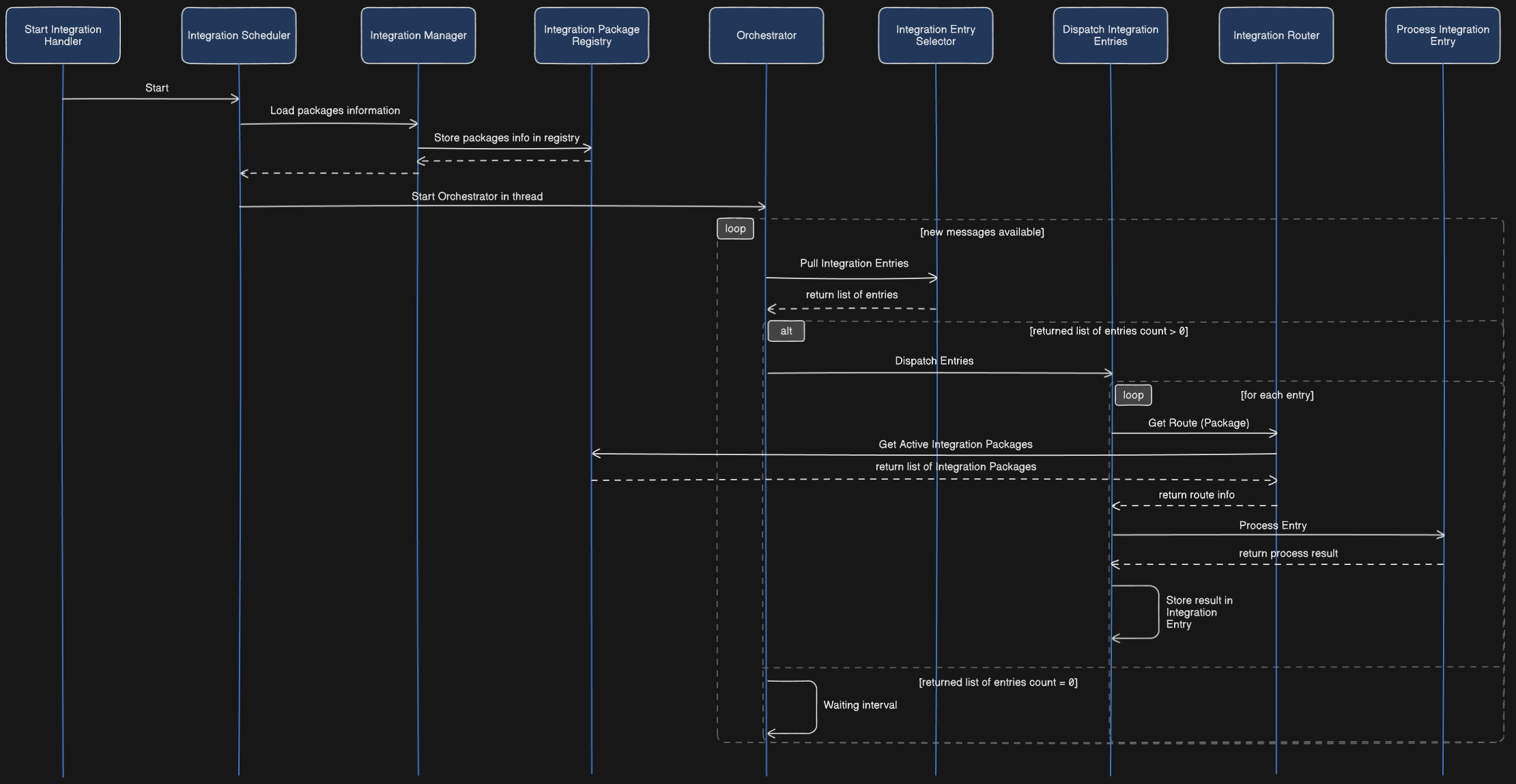
⚠️ This diagram is intended to illustrate the key components and the overall process flow at a higher level, rather than detailing every single C# class or method involved.
Let’s examine these steps in more detail.
Starting the Background Orchestrator
As previously mentioned, the StartIntegrationHandler initiates the Integration Scheduler. The Scheduler’s main responsibilities are:
- It calls the
Integration Managerto load information about the Integration Packages (e.g., GenericIntegrationPackage) from the database and caches it within anIntegration Package Registry. - It creates a new thread (to avoid blocking the Host’s main operations) that executes the
Orchestratorprocess.
Pulling Integration Entries
Once the orchestration logic begins, it enters a loop where its first task is to retrieve eligible integration entries from the database for processing. This retrieval logic resides in the stored procedure [CoreDataModel].[P_PullNextIntegrationEntry]. This procedure queries the T_IntegrationEntry table and returns one or more integration entries that are ready to be processed.
Analyzing this stored procedure reveals the involvement of another table, T_IntegrationEntryLock, alongside T_IntegrationEntry. This auxiliary table works in conjunction with the main entity table to track the current “processing” status of Integration Entries. When an Integration Entry is created, a record is added not only to the main table but also to this “lock” auxiliary table.
Since Integration Entries are stored in their own table within the SQL Server ONLINE database, it’s crucial to ensure that in environments with multiple running Hosts (e.g., Production), the same entries are not processed by different hosts concurrently. This is why the query employs SQL Hints such as UPDLOCK and READPAST. The UPDLOCK hint applies an update lock to the selected records, while READPAST instructs the query to skip records that already have an update lock. Consequently, if one Host is processing a specific entry, another Host will “read past” it and select the next available entry (or entries).
Furthermore, within the same query, you might observe fields like BatchId and ParentIntegrationEntryId.
Integration entries sharing the same BatchId are retrieved together by this procedure and processed sequentially by the orchestrator. This explains why the procedure might return more than one entry at a time.
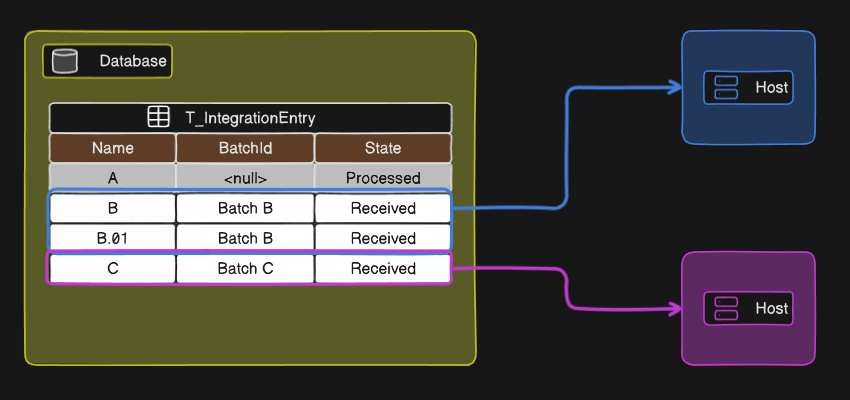
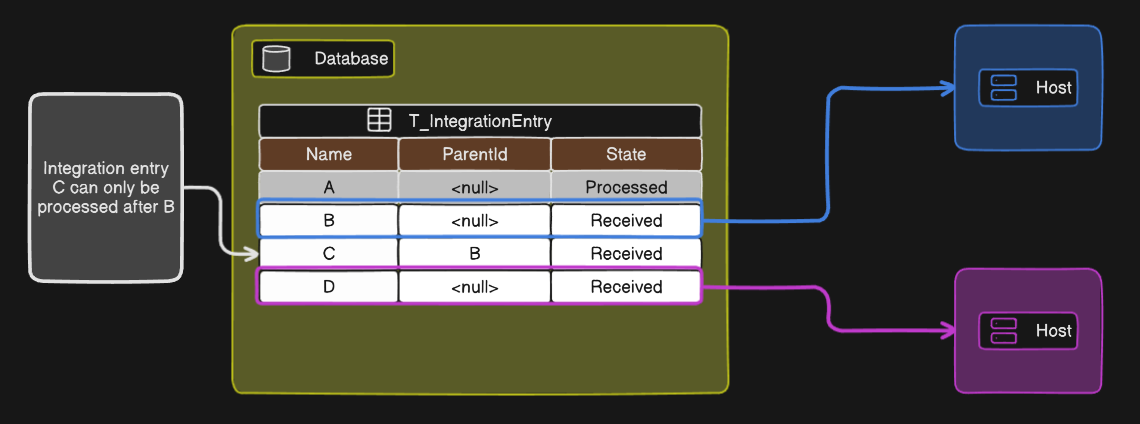
The ParentIntegrationEntryId field establishes a dependency chain between entries. If Entry B has Entry A as its parent, Entry A must be processed before Entry B becomes eligible for processing.
⚠️ Parent integration entry might not have been successfully processed
It’s important to note that the system doesn’t inherently prevent the processing of child entries if the parent entry has failed after multiple retry attempts. Implementing a “circuit breaker” or similar custom logic might be necessary in your projects to handle such dependencies and prevent unintended processing.
Dispatch and Process Integration Entries
After the pull stored procedure returns the integration entries, they are dispatched and processed. During the dispatch phase, for each entry, the system determines the responsible Integration Package based on the configuration in the IntegrationHandlerResolution table. Following this selection, the entry and its routing information are passed to the “Process Integration Entry” orchestration method, which executes the actual processing logic.
If the entry is processed successfully, its system state is updated to Processed, and the process concludes for that entry. If an error occurs during processing, the entry’s state is set to Failed. Additionally, if a custom error handling action is configured in the IntegrationHandlerResolution smart table, this action will be executed (e.g., to automatically set the entry to be retried after examining the error message).
Global Configurations and Wrap Up
To conclude this post, I’d like to highlight a couple of global configurations that can be adjusted if needed.
When the orchestrator doesn’t find any integration entries to process at a particular time, it waits for a specific duration before attempting to read new entries from the database again. This duration is known as the Polling interval and can be configured in the Config entry /Cmf/System/Configuration/Integration/PollingInterval/. The default value for this configuration is 60000, which translates to 60 seconds.
Another global configuration is the Number of parallel requests (Config entry /Cmf/System/Configuration/Integration/NumberOfParallelRequests/). This setting determines the maximum number of integration entry processing requests that each MES Host instance can handle concurrently. Therefore, the total number of parallel requests your system can handle is the product of this configuration value and the number of active MES Host instance in your environment. When an MES Host reaches its configured limit, it will stop pulling new integration entries until a processing slot becomes available. The following diagram illustrates an example with two hosts, both using the default value for the number of parallel requests.
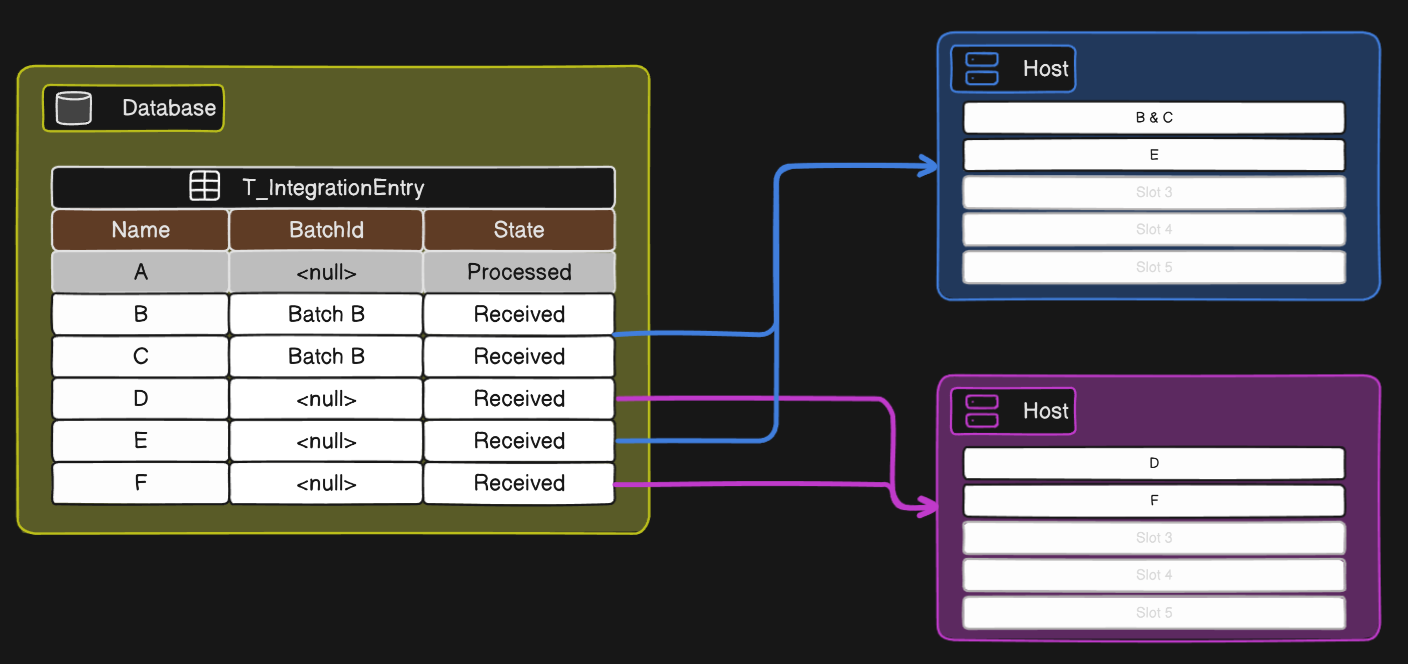
ℹ️ One Batch, One Slot
A single batch containing multiple integration entries will only consume one processing slot at a time, as illustrated by the “B & C” example above.
⚠️ Changing default values
In most scenarios, the default configuration values are adequate. However, you can modify these values to better suit your specific needs. It’s crucial to exercise caution when adjusting the number of parallel requests to avoid negatively impacting the system’s normal operation. If possible, it’s highly recommended to conduct thorough load and stress tests in a non-production environment before deploying any changes to these configurations in production.
That’s all for now! I hope this deep dive into the system integration engine has provided valuable insights. If you’re interested in learning more about related topics such as low-code integration, custom integration packages, or anything else, please feel free to reach out!
Author
Hi! My name is Ricardo Cunha. ✌️
I joined Critical Manufacturing back in 2013. I started my journey as a Software Engineer, progressed to Tech Lead, and currently serve as a Technical Architect in the Solutions Delivery area, providing technical guidance for CM MES deployments.
You can check me on LinkedIn
